Leveraging Transformative AI to Support Curriculum Alignment

This has been a month filled with exciting conversations and sparks of new collaboration! First at UNESCO’s Digital Learning Week, and then at the mEducation Alliance Symposium, I presented updates on Learning Equality’s ongoing collaborative efforts to streamline and automate the process of curriculum alignment, an area we began exploring with UNHCR back in 2018. We’ve made huge strides forward over the past year, and I was energized to receive enthusiastic responses from those who know from firsthand experience how much more efficient and effective these new tools could make this labor-intensive endeavor.
So what is curriculum alignment, and why is it important?
When implementing an edtech project, either you invest in creating a whole new set of teaching and learning materials yourself, or you take advantage of a wealth of Open Education Resources that have been created by others and released under free and open licenses. These open resources, however, were generally created with specific contexts in mind, and are scattered across various sources on the Internet, each of which is organized differently. Curriculum alignment is the process of organizing, adapting, and contextualizing resources to the standards and learning objectives of the national curriculum or textbook that is relevant to the learners and educators being served by a program — and is a critical ingredient in enabling discovery and use of these resources to support effective learning.
Learning Equality’s open-source product suite Kolibri includes an easy tool, Kolibri Studio, for aligning content from the Kolibri Library of nearly 200,000 open resources, along with one’s own materials, to specific curricular standards. While this process is simpler and more fluid than the spreadsheet-based methods used by many who do alignment work, it still involves tedious and time-consuming tasks, which can raise cost and capacity barriers. When adding on to that the need for rapid alignment to new standards when a crisis arises, it becomes clear why UNHCR has been strongly advocating for and supporting this work towards automation.
So what parts of this process are we automating?
The first area we set out to automate, culminating in a Kaggle machine learning competition we co-hosted earlier this year, was the matching of resources to specific objectives and topic areas within a target curriculum. We now have some very efficient and effective multilingual recommender models that are openly released, and also being integrated into Kolibri Studio to support streamlined workflows.

The next piece of the puzzle we’re tackling is digitizing and extracting curricular structures from source documents in a way that can be used meaningfully within an educational platform. Manually extracting a standardized taxonomy or topic tree from a curriculum guide provided as paper or even PDF can be extremely time-consuming, but is, of course, a prerequisite to the process of curriculum alignment itself.
I’m excited to share that we’re now developing a very effective way to extract meaningful, machine-usable structures from documents like the one shown below, which we illustrate with an animation of the automated extraction process.


The key technology we leverage to support this process is GPT-4, the Large Language Model that underlies the advanced version of ChatGPT. While these new LLMs are being referred to as “Generative AI”, and the use cases most frequently discussed involve chat and coding, we’re using GPT-4 here for something we might instead call “Transformative AI”, which taps into the incredible ability these models have to transform text between formats and schemas, and extract structured data from raw unstructured text. Particularly for organizations like Learning Equality that work to support low-resource, offline contexts at scale — which can raise barriers for direct use of AI tools by our beneficiaries — finding ways to leverage the benefits of this tech for catalytic purposes, enabling us and our partners to do our work more efficiently and effectively, can be very powerful.

What about other languages?
While the generative capabilities of Large Language Models often have strong quality biases across languages, with the dominance of English and other European languages in their training sets, use cases that involve transformation seem to be more robust and still able to produce quality results across a diverse range of languages. Below, you can find an illustration of the extraction process (without any additional training or refinement) operating on an excerpt from the Jordanian curricular standards in Arabic.
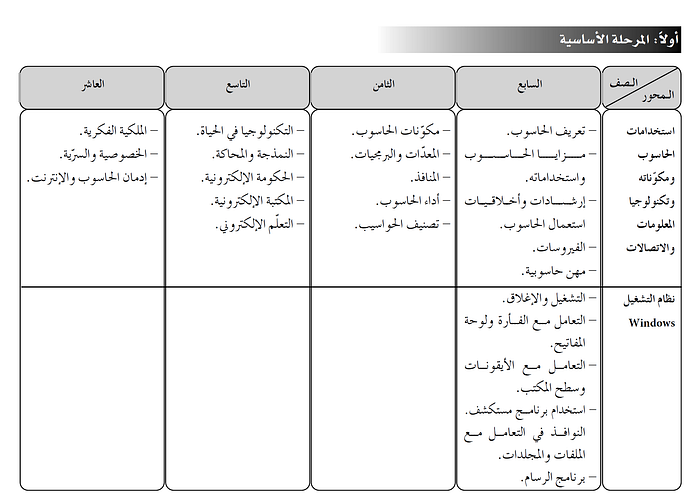

What’s next?
We’re committed to building out these tools and getting them into the hands of practitioners, to benefit learners and educators around the world. So we’d love to chat if you have projects where you’re either:
- Engaging in curriculum alignment and want to explore streamlining the process, or
- Collecting datasets around curricular metadata or OER and want to share to support further training of these models.
We’re also actively seeking funding for further development and release of these tools as open-source public goods, for use across any platform, so please get in touch if you have mutual interest and see opportunities to support these efforts.

